
Elasticsearch supports several object storage solutions or vendors out of the box for taking snapshots of your data, or for backups. It is as easy as installing the correct plugin, followed by a proper configuration. Using the supported vendor’s storage option is easy and convenient. But, can you take a snapshot into Linode object storage as an S3 compatible solution with Elasticsearch? Let’s find out in this post.
Introduction
As a user, you may often end up using a different object storage solutions for various reasons. Whether it is because of limited access, project decisions and definitions, or architecture requirements, using a custom object storage for Elasticsearch can be complicated.However, if your object storage implementation claims to be S3-compatible, you can try to configure it as a snapshot repository using the Elasticsearch S3 plugin . The plugin is developed to support AWS S3 repositories. Still, other vendors and developers try to get into the market by creating their object storage compatible with AWS S3 API’s so the user does not have to change their code/application/architecture …
One of such implementations has Linode , which offers their own object storage solution for their users. As I am using their services for my own projects, let’s have a look at how I connect their object storage to Elasticsearch as a repository for snapshots.
How to
Based on the official Elasticsearch snapshot documentation, there is no support or configuration section of other (than listed in the documentation) object storage services. This is absolutely understandable, as supporting all of the available vendors wouldn’t be possible. Elasticsearch focuses on the most significant players, and that is just fine.On the other side, Elastic develops a S3 plugin which works with local object storage like Minio . Minio is one of the S3 compatible and open-source solution which you, as a user, can host at your location or data center and use for the snapshots. This is convenient when you cannot send your data out of the data center or have an air-gapped environment, which has no connection to the outside world.
The critical piece of the setup is in the official documentation for Minio setup in ECE environment. Note, not all in the linked guide is required for our needs, and I will guide you through the necessary steps.
1. S3 plugin
Make sure that all nodes in your Elasticsearch cluster, which holds data have the S3 plugin installed. This is an important part that adds required functionality for accessing S3 compatible object storage solutions. To install the plugin, follow the documentation .
2. Linode object storage access
Create your access and secret key for the object storage. All the steps are explained in the
documentation . Copy and save both values for the later configuration.

Create a bucket where you will store the snapshot and choose the
location .
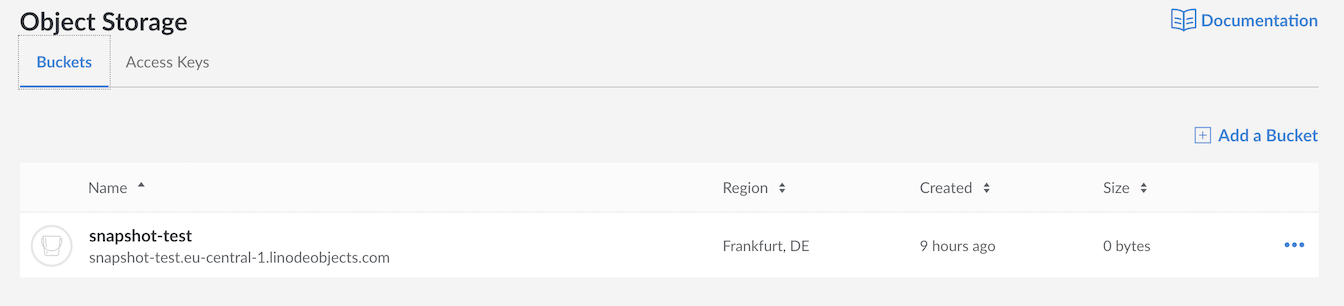
3. Create and configure the repository
To register our object storage as a snapshot repository , we will use an API call which you can find in the Minio setup documentation for ECE setup.
This is the actual ’trick’ to register third party S3 compatible object storage in Elasticsearch. The UI does not support all parameters, and you need to use the API call.
PUT /_snapshot/my_linode_repository
{
"type": "s3",
"settings": {
"bucket": "snapshot-test",
"access_key": "<access_key>",
"secret_key": "<secret_key>",
"endpoint": "eu-central-1.linodeobjects.com",
"protocol": "http"
}
}
{
"acknowledged" : true
}
Verify the repository POST /_snapshot/my_linode_repository/_verify. You have to make sure that you will see all nodes holding the data in the response.
{
"nodes" : {
"oFj7NfCtSyaNScDpKrhNUA" : {
"name" : "node-1"
},
"iBPrGGUEQb6wjjrNYQ6vBA" : {
"name" : "node-2"
},
"SwdoXxZFSQ6IIGdauVNbGg" : {
"name" : "node-3"
}
}
}
You can also check available repositories which are configured in the cluster using another API call
GET /_snapshot/
{
{...},
"my_linode_repository" : {
"type" : "s3",
"settings" : {
"bucket" : "snapshot-test",
"endpoint" : "eu-central-1.linodeobjects.com",
"protocol" : "http"
}
}
}
… or check the
Snapshot and Restore UI in Kibana in the Repositories panel.
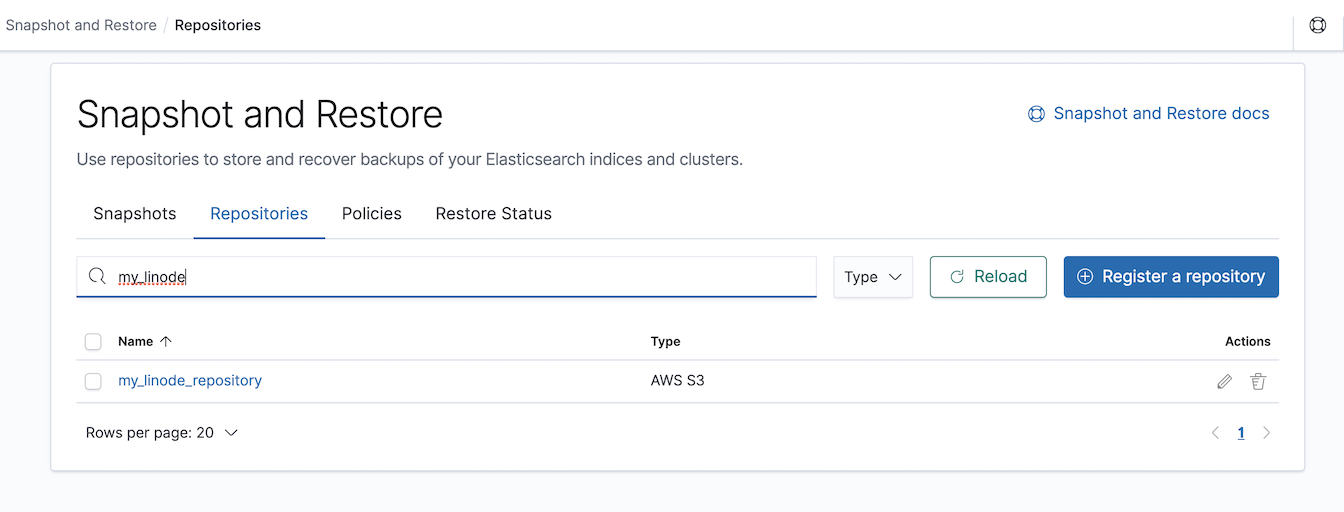
Your repository is now configured and ready to be used, taking a snapshot in the following step.
4. Take a snapshot
The easiest way is to take a snapshot using a simple API call . Some would argue that it is easier to take s snapshot using the Kibana UI, and I leave the decision to you. To take a snapshot, execute a simple API call and optionally add a list of indices or other available options. Feel free to check the full documentation .
PUT /_snapshot/my_linode_repository/snapshot_1
{
"indices": "filebeat-7.8.1-2020.08.*",
"ignore_unavailable": true,
"include_global_state": false
}
After the execution, check on the progress of the snapshot with another API call.
GET /_snapshot/my_linode_repository/snapshot_1
{
"snapshots" : [
{
"snapshot" : "snapshot_1",
"uuid" : "u3HXdSHSSW2vcqb8Du7MVQ",
"version_id" : 7080199,
"version" : "7.8.1",
"indices" : [
"filebeat-7.8.1-2020.08.17",
"filebeat-7.8.1-2020.08.19",
"filebeat-7.8.1-2020.08.21",
"filebeat-7.8.1-2020.08.12",
"filebeat-7.8.1-2020.08.14",
"filebeat-7.8.1-2020.08.11",
"filebeat-7.8.1-2020.08.16",
"filebeat-7.8.1-2020.08.23",
"filebeat-7.8.1-2020.08.18",
"filebeat-7.8.1-2020.08.15",
"filebeat-7.8.1-2020.08.24",
"filebeat-7.8.1-2020.08.22",
"filebeat-7.8.1-2020.08.13",
"filebeat-7.8.1-2020.08.20"
],
"include_global_state" : false,
"state" : "IN_PROGRESS",
"start_time" : "2020-08-24T15:17:39.608Z",
"start_time_in_millis" : 1598282259608,
"end_time" : "1970-01-01T00:00:00.000Z",
"end_time_in_millis" : 0,
"duration_in_millis" : 0,
"failures" : [ ],
"shards" : {
"total" : 0,
"failed" : 0,
"successful" : 0
}
}
]
}
In any case, Kibana offers a great UI for Snapshot management which I strongly suggest having a look at. The Kibana application will significantly simplify your daily tasks and is more accessible for less technical people in your team.
As an example, there is a view of your snapshots and the detail of each snapshot taken.
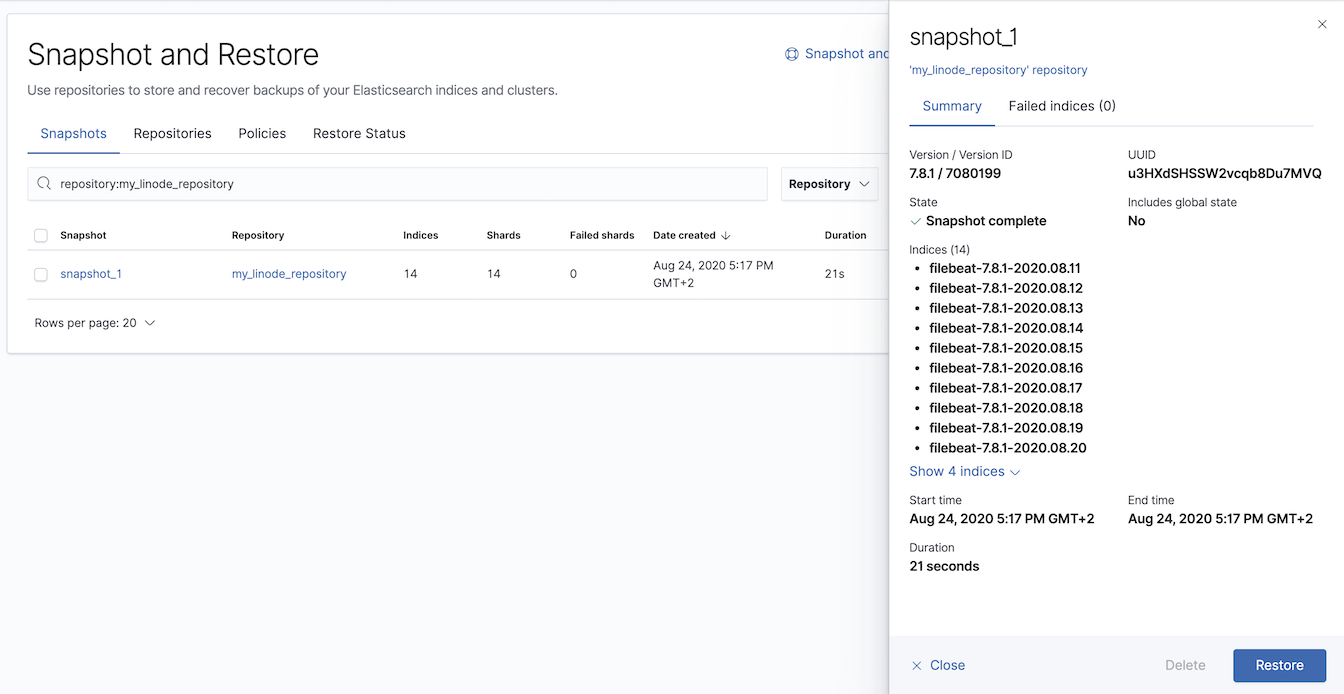
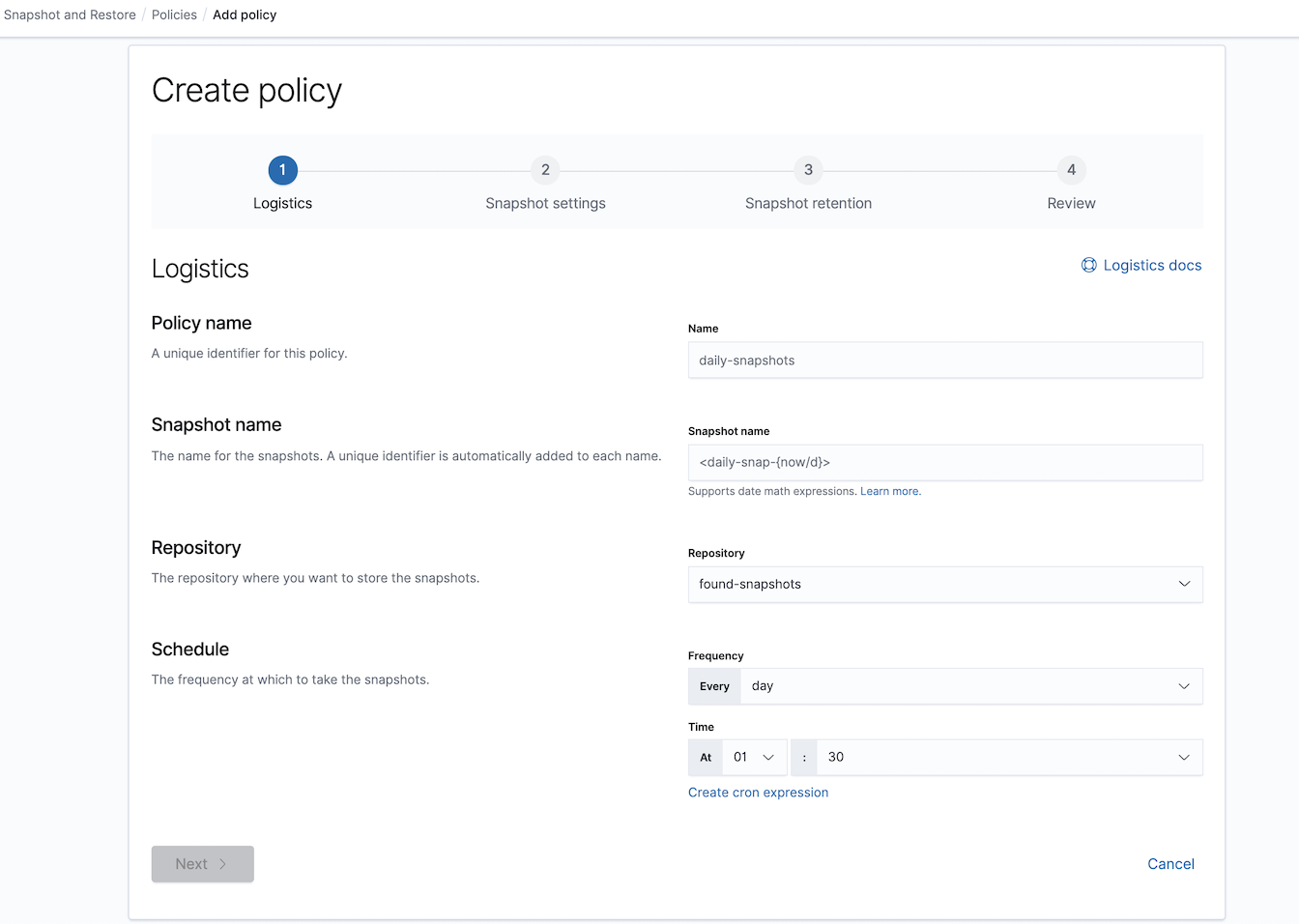
If you want to create a snapshot from the data periodically, do not forget to set up a snapshot policy using Snapshot lifecycle management ( SLM ).
Summary/FAQ
- Does it work? Yes, but test it for yourself.
- What types of environment the setup in the post work? You can run this in any environment where you are able to install S3 plugin, and you are able to connect to the Linode object storage.
- Is Linode object storage officially supported by Elastic? No. Elastic Supports following repository backends.
- Can you use it in your (prod) environment? It depends. It depends on many factors and what you expect from the final solution. It depends on your team and the ability to make sure that you test everything, and you know how to make it reliable and resilient.
- Will the same approach work on other Object storages? I do not know. On the other hand, no one will stop you from testing it using the above approach and figure it out. Then, let me know.
- Is it fun? Definitely yes.
I hope you have discovered something useful Today and if you have any comments or thought, let me know in the comments.